百度出品,基于DeepSeek-OCR改进,支持一次性解析超长文档、多页PDF,单图640切片+多页1024两种模式,SGLang部署兼容OpenAI API
简介
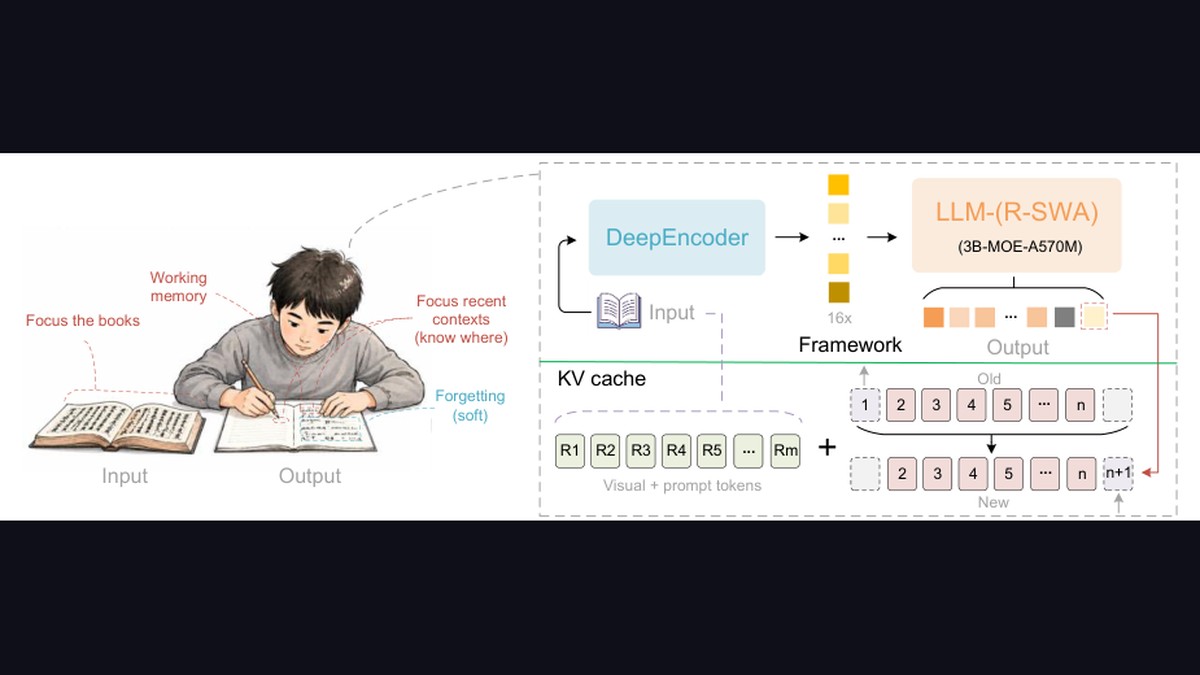
Unlimited OCR 是百度开源的文档 OCR 解析模型,旨在将 DeepSeek-OCR 的能力进一步推进,实现一次性长文档解析(One-shot Long-horizon Parsing)。2026年6月22日发布,MIT 协议。
支持单图解析、多页文档联合解析和 PDF 全文解析,提供 Transformers 直接推理和 SGLang 服务端部署两种使用方式。
核心特性
- 单图双模式:
gundam(base_size=1024, image_size=640, crop_mode=True)适合一般文档;base(image_size=1024, crop_mode=False)适合高精度场景 - 多页/PDF 解析:多页文档统一使用 base 模式,自动处理页面间上下文
- 长文本输出:max_length 支持到 32768 tokens
- SGLang 部署:兼容 OpenAI API 格式,支持流式输出,适合生产环境批量推理
- 批量推理:
infer.py一键启动服务端 + 并发请求处理整个图片目录或 PDF
技术栈
- 推理框架:Transformers 4.57.1 / SGLang
- GPU 要求:NVIDIA CUDA(测试环境 CUDA 12.9)
- Python:3.12.3
- 精度:bfloat16
- 注意力后端:fa3(Flash Attention 3)
快速开始
from transformers import AutoModel, AutoTokenizer
model_name = 'baidu/Unlimited-OCR'
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(model_name, trust_remote_code=True, use_safetensors=True, torch_dtype=torch.bfloat16)
model = model.eval().cuda()
model.infer(tokenizer, prompt='<image>document parsing.', image_file='your_image.jpg',
output_path='./output', base_size=1024, image_size=640, crop_mode=True,
max_length=32768, save_results=True)
链接


暂无评论