轻量级块扩散模型,专为 LLM Speculative Decoding 设计,支持 vLLM/SGLang/MLX,已适配 20+ 主流大模型
DFlash: Block Diffusion for Flash Speculative Decoding
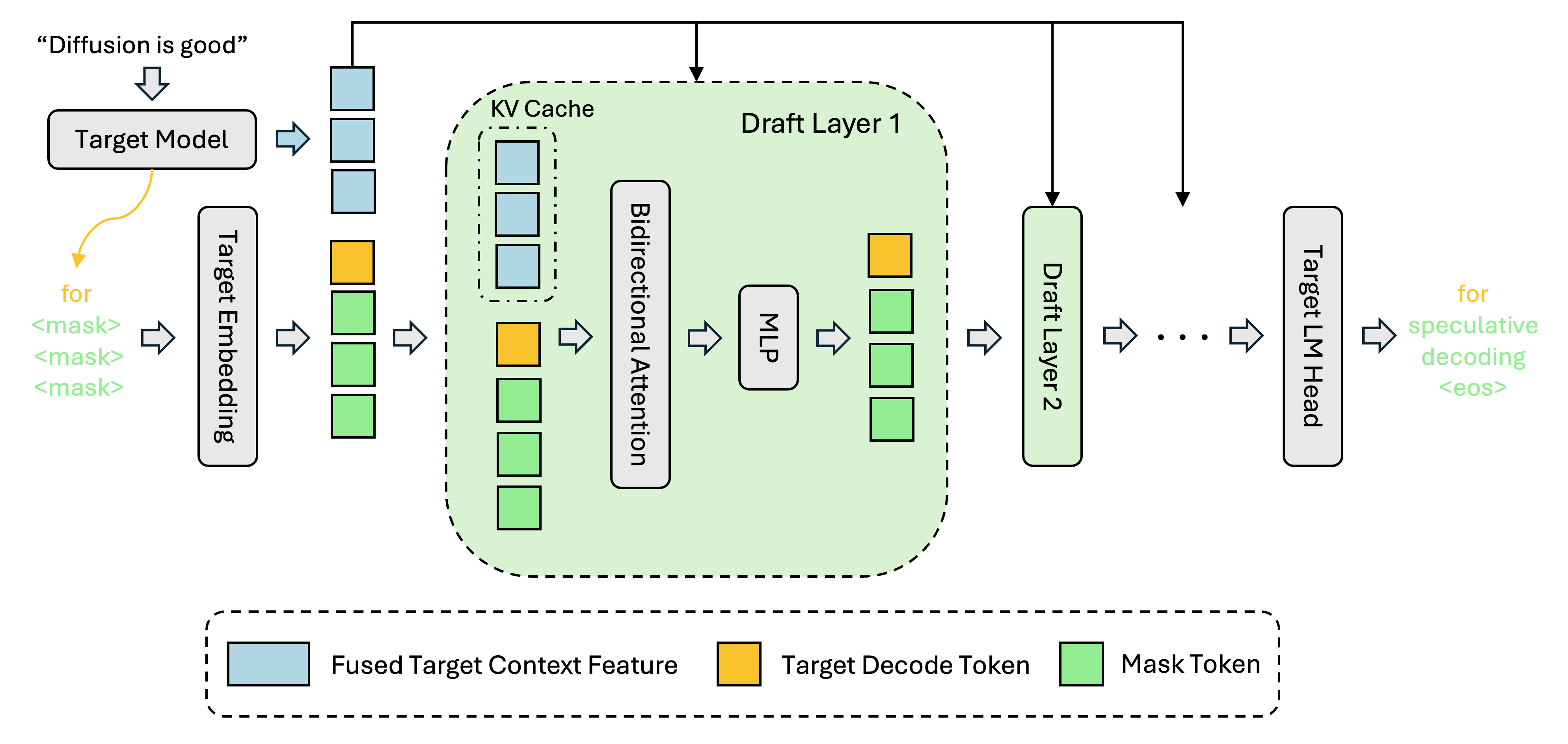
DFlash 是一个轻量级块扩散模型,专为 LLM 推测解码(Speculative Decoding)设计,实现高效高质量的并行 Draft 生成。
核心亮点
- 🚀 显著加速推理 — 通过块扩散模型并行生成 draft tokens,大幅提升 LLM 推理速度
- 🔧 即插即用 — 支持 vLLM、SGLang、Transformers、MLX(Apple Silicon)多种后端
- 🧠 广泛模型支持 — 已适配 20+ 主流大模型
支持模型(部分)
| 模型 | 状态 |
|---|---|
| Kimi-K2.5 | ✅ |
| Qwen3.5 全系列(4B~122B) | ✅ |
| Gemma-4-26B/31B | ✅ |
| MiniMax-M2.5 | ✅ |
| DeepSeek-V4 | 即将支持 |
| GLM-5.1 | 即将支持 |
快速开始
# vLLM 后端安装
uv pip install -e ".[vllm]"
# SGLang 后端
uv pip install -e ".[sglang]"
# Apple Silicon MLX
pip install -e ".[mlx]"
相关链接
- 📄 论文
- 📝 Blog
- 🤗 HuggingFace Models
⭐ 3233 Stars | Python


暂无评论