站内搜索「爬虫」共 7 条结果



Rust 编写的开源 headless 浏览器,内存仅 30MB、启动瞬开、内置反检测与跟踪器拦截,单二进制无依赖,兼容 Puppeteer/Playwright,适合大规模网页抓取与 AI Agent 自动化
点击获取 ^_^
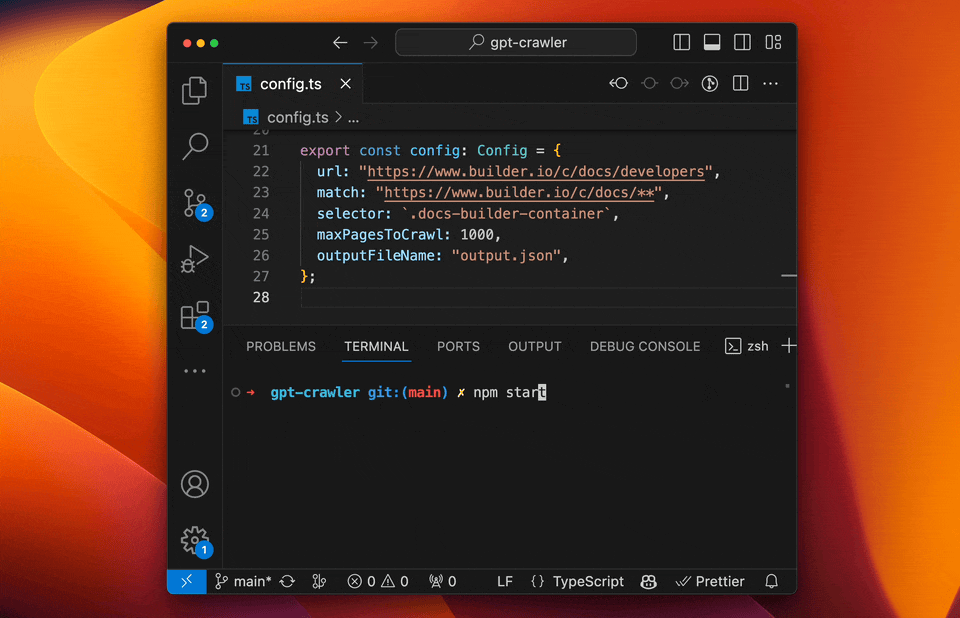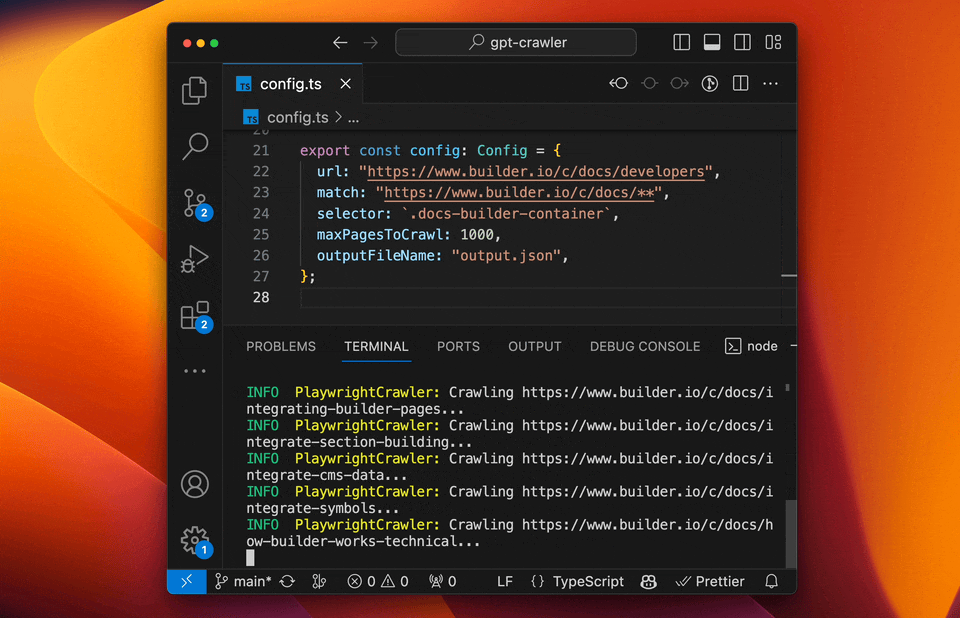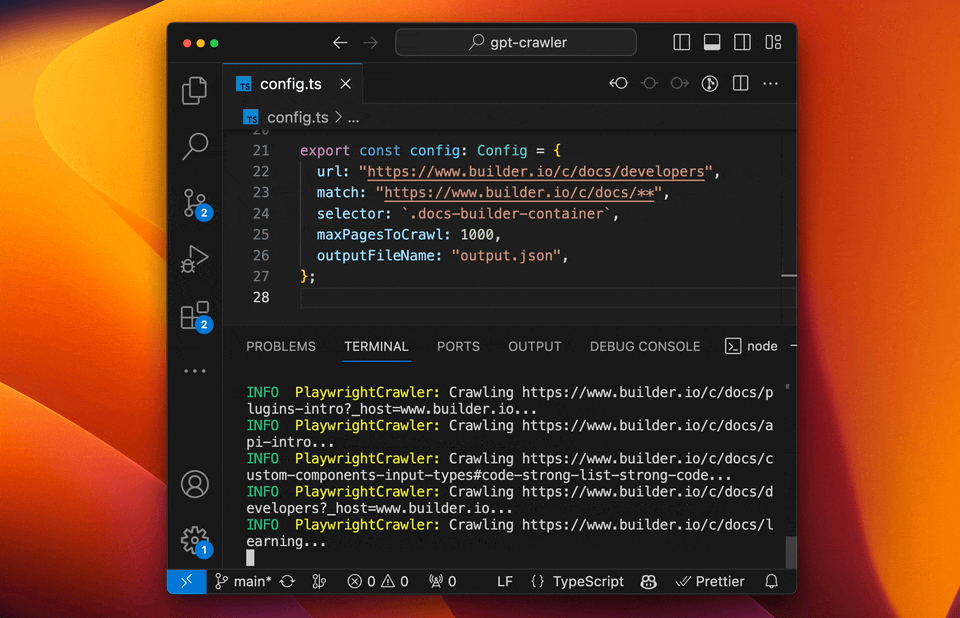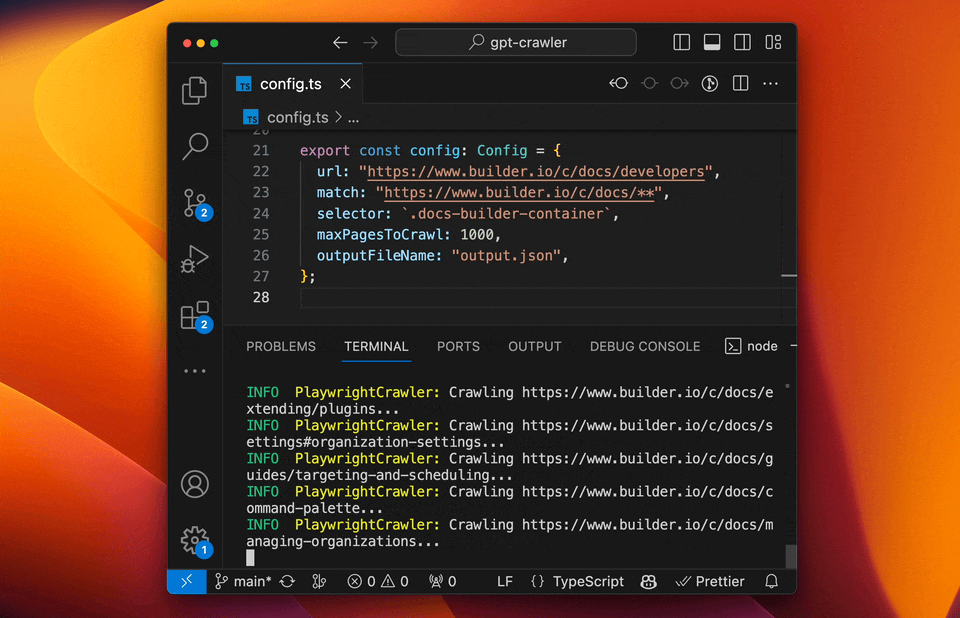
它能从一个或多个网址爬取网站内容,然后生成JSON文件格式。这样爬取的内容可以直接导入到GPTs知识库中,方便你创建自定义知识库的GPTs。 比如你有自己的网站或者资料库,但是整理起来太麻烦,就可以使用这个工具。
点击获取 ^_^
北极熊扫描器是由“广州白狐网络科技有限公司”开发的一款信息安全审计工具,支持多线程获取网站信息,提供网站爬虫、后台扫描、CMS识别、安全检测,后台测试,代码审计、域名侦查等功能,扫描结果可直接将数据导出为“电子表格”,自动化任务执行上能够提升安全人员检测的便利性。
点击获取 ^_^